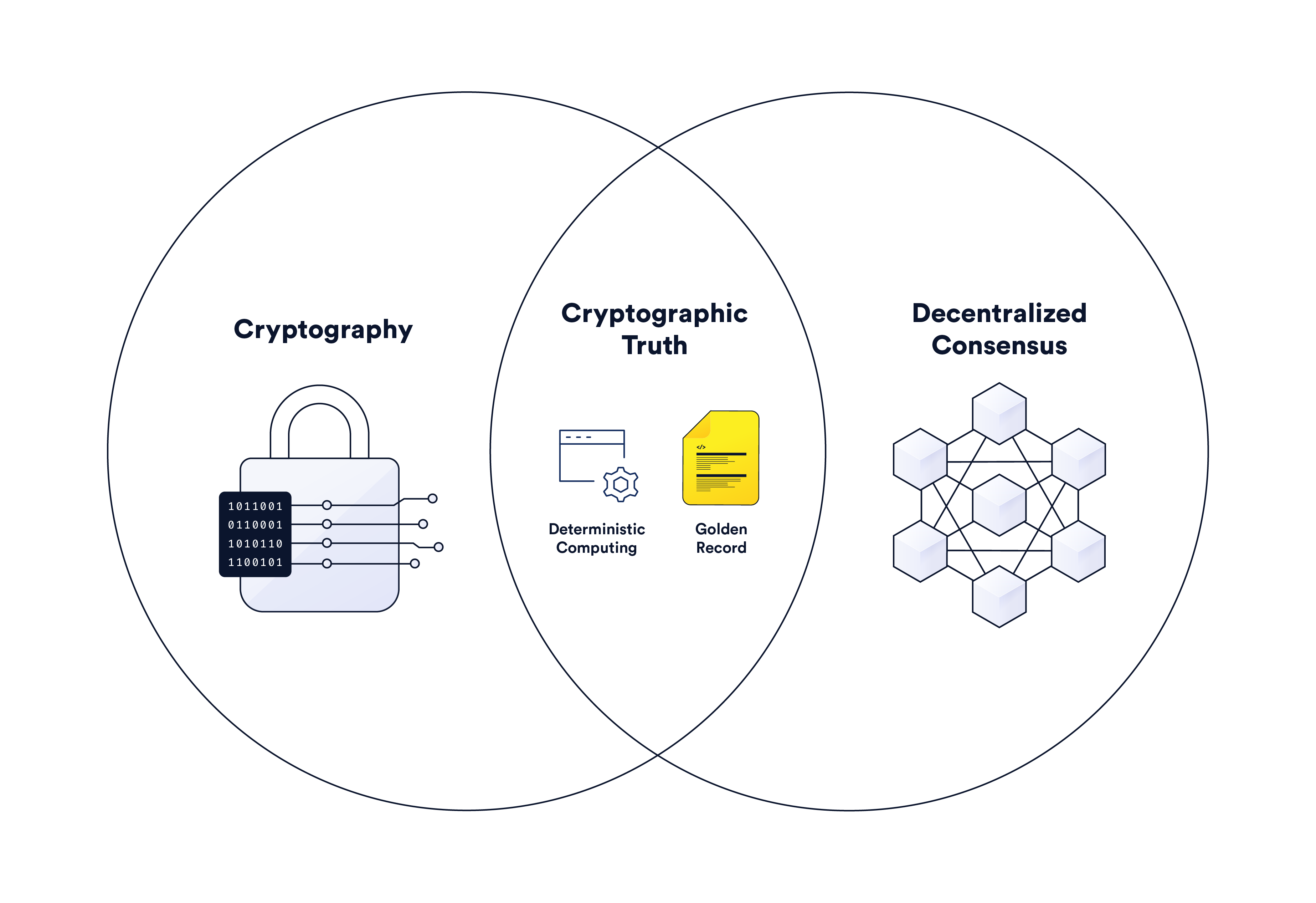
Trust minimization is a valuable security property that blockchain technology is uniquely positioned to generate—replacing handshakes, brand reputation, and paper contracts with guarantees based on computer code, cryptography, and decentralized consensus. These superior guarantees provided by blockchains form the basis of cryptographic truth.
Blockchains have succeeded in bringing trust minimization to new use cases including monetary policy (e.g. Bitcoin) and digital asset trading. However, blockchains have historically struggled to maintain trust minimization for use cases that require speeds and costs comparable to traditional computing systems. These scalability limitations can be felt by users in the form of high transaction costs and cause developers to doubt whether blockchains can support high-value use cases that hinge on handling data in real-time.
With the ultimate goal of unlocking blockchain technology for all users and use cases, scalability is at the forefront of blockchain research and development as a key element in smart contracts becoming the preferred backend of major industries such as finance, supply chain, and gaming, and beyond. The following post provides an overview of blockchain scalability, focusing on how blockchains differ from traditional computing before outlining the advantages and tradeoffs of different approaches to scaling the execution, storage, and consensus layers of blockchains.
Blockchains vs. Traditional Computing
Before discussing how to scale blockchains, it’s important to first understand why blockchain computing is fundamentally different from traditional computing. In general, blockchains are valuable for three reasons:
- Deterministic computation—predefined coded logic executes exactly as written with a very high level of certainty.
- Credible neutrality—there is no central administrator and no special network privileges, meaning anyone can submit transactions without fear of censorship or discrimination.
- End-user verification—the historical and current state of the blockchain’s ledger and the code underpinning the client software are auditable by anyone in the world.
At a more technical level, blockchains are tasked with managing an internal ledger of data, which can represent asset ownership, contract state, or simply raw information. Most blockchain networks are managed by two overlapping yet distinct sets of participants: block producers and full nodes.
Block producers gather unconfirmed transactions submitted by users, check their validity, and place them into data structures called blocks. Block producers are generally referred to as miners in Proof-of-Work (PoW) chains or validators in Proof-of-Stake (PoS) chains, with PoW and PoS acting as Sybil-resistance mechanisms to ensure that blockchain ledgers remain live and immune to censorship.
The blocks submitted by block producers are then accepted or rejected by full nodes—entities that independently store a full copy of the chain’s ledger and continually validate new blocks but are not required to participate in block production. Full nodes are run by most block producers but also include end-users and key economic actors such as exchanges, RPC providers, and stablecoin issuers. Ultimately, full nodes keep block producers honest by rejecting invalid blocks, even in a situation where the majority of block producers are malicious. This makes the creation of invalid blocks a waste of time and money, assuming a sufficient number of honest full nodes exist.
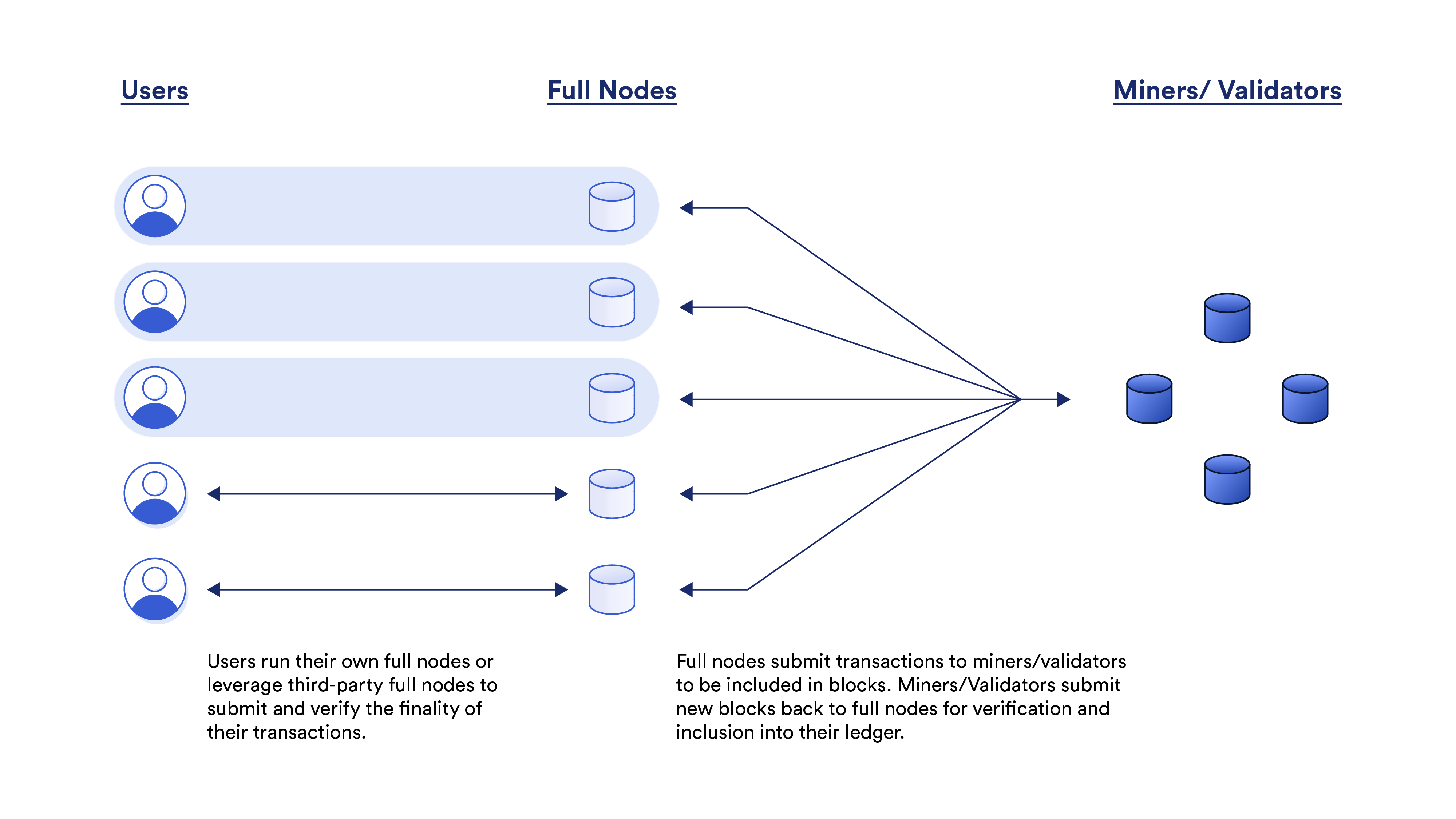
Furthermore, the separation of full nodes and block producers prevents miners/validators from corrupting the blockchain by arbitrarily changing the protocol’s rules. This is part of a checks and balances system where block producers only have the power to order transactions but do not dictate the rules of the blockchain. The rules are governed by the full node community, which ideally anyone can easily participate in. Reducing hardware requirements is crucial to lowering the barrier to entry for running a full node, which is historically how blockchains have remained decentralized—a critical component to generating trust minimization. However, decentralization is also the property that generally makes blockchains slow, since the network can for the most part only operate at the speed of the slowest node. This dynamic is described by the “blockchain trilemma”—also called the scalability trilemma—which states that traditional blockchains can only maximize two out of the three properties: scalability, decentralization, and security.
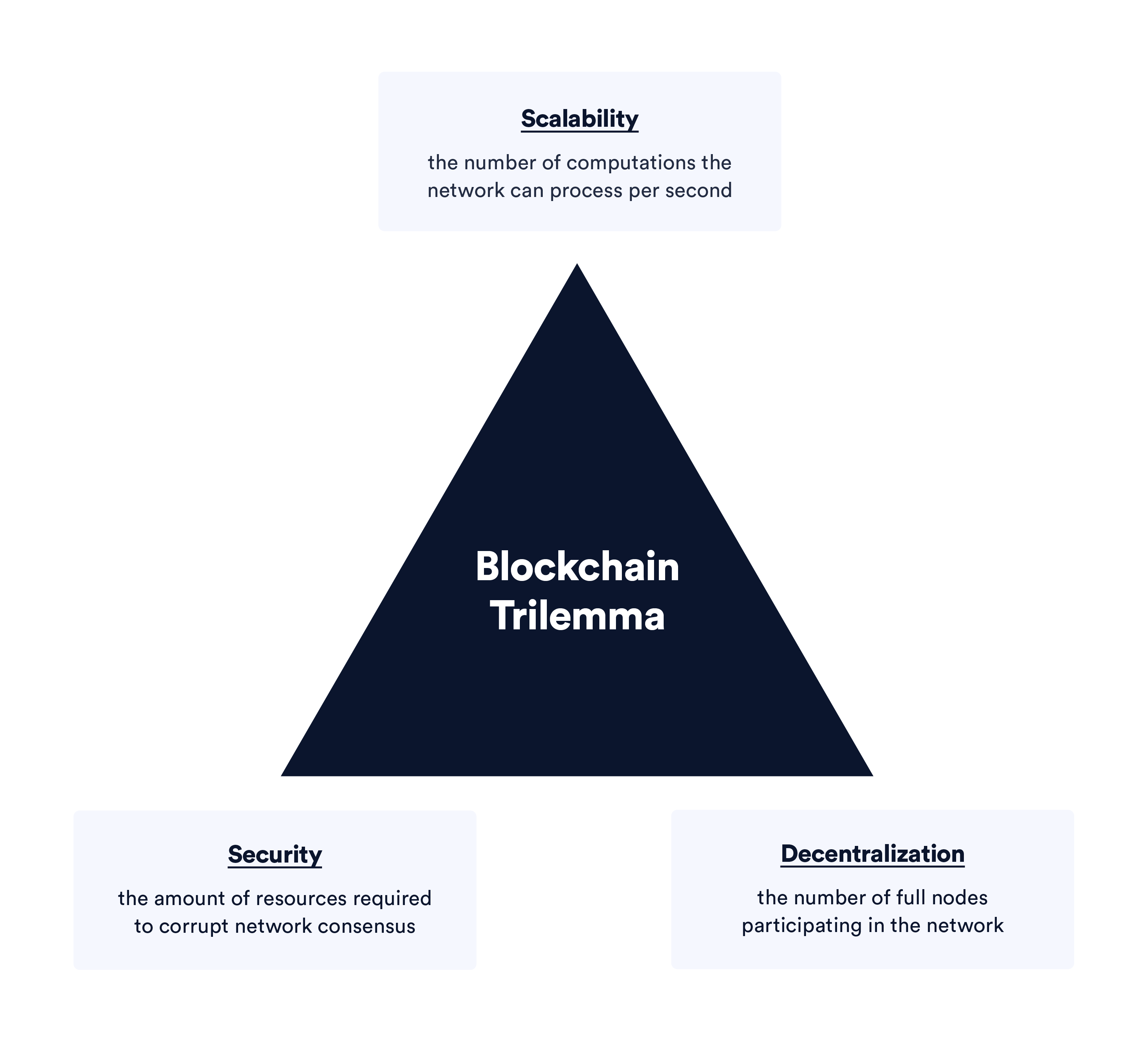
One limitation of traditional blockchain models is that achieving scalability usually requires sacrificing decentralization, security, or some degree of both. For instance, a scalable and decentralized network will need to incentivize a large number of active participants to achieve high security. A scalable and secure network will generally raise the cost of running a node at the expense of decentralization. Furthermore, decentralized and secure networks keep node requirements low and the cost of attacks high but end up with scalability bottlenecks.
Unlike blockchains, traditional computing environments do not have to worry about decentralization since maximizing trust minimization is not their primary objective. This is why traditional computing networks are generally centralized and operated by for-profit companies, naturally reducing their cost and increasing their speed since the network is managed by a single entity that doesn’t have to design around making its computation independently verifiable by end-users.
As a result, the trust model of traditional computation environments is based on brand and legal contracts. In contrast, blockchain trust models rely on cryptography and game theory, offering independent verifiability and often supporting direct user participation. The trust model of traditional computing environments is simply not compatible with blockchain networks since they are subject to chokepoints such as external influence, single points of failure and control, and processes that can’t be audited by users.
These dynamics get at the essence of blockchain scalability: How do blockchains achieve the speed and costs of traditional computing environments while still maintaining strong trust-minimization properties of security and decentralization?
Three Key Properties of Blockchain Scaling
Blockchain scaling can be broken down into three general categories: execution, storage, and consensus. Below, we define each property and look at the core problem it seeks to solve. In practice, scaling one property is often dependent on or results in the scaling of one or two other properties.
Blockchain Execution
Blockchain execution is the computation required to execute transactions and perform state changes. Transaction execution involves checking the validity of transactions (e.g. verifying signatures and token balances) and executing the on-chain logic needed to calculate state changes. State changes are when full nodes update their copy of the ledger to reflect new token transfers, smart contract code updates, and data storage.
The scalability of blockchain execution is commonly thought of in terms of transactions per second (TPS), but on a more general level, it refers to the number of computations per second since transactions can vary in complexity and cost. The more transactions that flow through a network, the more computations that need execution at any given time.
When scaling the execution layer, the main problem to solve is how to achieve more computations per second without substantially increasing the hardware requirements on individual full nodes that validate the transactions in blocks.
Blockchain Storage
Blockchain storage refers to the storage requirements of full nodes, which maintain and store a copy of the ledger. Blockchains have two general forms of storage:
- Historical data encompasses all the raw transactions and block data. Transaction data includes the origin and destination addresses, the amount sent, and the signature of every individual transaction. Block data includes the list of transactions and metadata from a specific block, such as its Merkle root, nonce, previous block hash, etc. Historical data doesn’t typically require quick access, and there only needs to be at least one honest entity making it available for download.
- Global state is a snapshot of all the data that smart contracts can read from or write to, such as account balances and the variables within all smart contracts. Global state can be generally thought of as the database of a blockchain, which is required to validate incoming transactions. State is commonly stored within tree structures (e.g. Merkle trees) where access and modifications can be easily and quickly made by a full node.
Full nodes need access to historical data in order to sync to the blockchain for the first time and global state in order to validate new blocks and execute new state changes. As the ledger and associated storage grow, computation of state becomes slower and more expensive because nodes require more time and computations to read from and write to state. If a node’s memory storage becomes full, it will need to use disk space storage, which further slows down computation since nodes need to swap between storage environments during execution.
Blockchain Consensus
Blockchain consensus is the method by which nodes in a decentralized network reach an agreement on the current state of the blockchain. Consensus is mostly concerned with achieving an honest majority in the face of a certain threshold of malicious actors and reaching finality; i.e., transactions are accurately processed and highly unlikely to ever be reversed. Blockchain consensus is generally designed around minimizing communication overhead in order to increase the upper bound on decentralization for stronger Byzantine fault tolerance and lower the time to finality for faster settlement.
When scaling the consensus layer, the main problem to solve is how to reach finality faster, cheaper, and with more trust minimization—all in a predictable, stable, and accurate manner.
- Deutsche Telekom AG Is Now One Of The Main Data Providers To Chainlink, LINK Hits New Highs
- By The End Of 2020, LINK Holdings By Whales Have Declined Around 10% But Chainlink Price Won’t Be Dumped